Teoria de Lenguajes de Programacion y Metodos de Traduccion I
Este material está diseñado para proporcionar a los estudiantes las bases necesarias para analizar, diseñar e implementar la fase de Analizador Léxico de un Compilador, de acuerdo con las exigencias del entorno empresarial.
Fundamentación
El curso se centra en establecer los fundamentos esenciales que capacitarán al estudiante para abordar la fase del Analizador Léxico de un Compilador. Se explorarán temas clave como Lenguajes, Lenguajes regulares y expresiones regulares, Autómatas deterministas y no deterministas, el manejo de la herramienta Flex, y finalmente, la definición formal de una gramática.
Sumilla
Este curso, de naturaleza teórica, aborda los siguientes temas:
- Lenguajes, Lenguajes regulares y expresiones regulares.
- Autómatas deterministas y no deterministas.
- Manejo de la herramienta Flex.
- Definición formal de una gramática.
Logro General de Aprendizaje
Al término del curso, los estudiantes serán capaces de utilizar las reglas gramaticales para determinar el orden de las cadenas mediante la herramienta Flex.
Unidades y Logros Específicos de Aprendizaje
Unidad de Aprendizaje 1: Lenguajes, Lenguajes regulares y expresiones regulares
En esta unidad, los estudiantes desarrollarán habilidades para formar unidades lógicas llamadas Tokens, leyendo los caracteres de un programa de un lenguaje de programación mediante expresiones regulares.
Unidad de Aprendizaje 2: Autómatas deterministas y no deterministas
Los estudiantes aprenderán a describir procesos para el reconocimiento de patrones de cadenas para formar los Tokens de un lenguaje de programación.
Unidad de Aprendizaje 3: Manejo de la herramienta Flex
En esta unidad, los estudiantes realizarán el análisis léxico sobre cada frase de un programa de un lenguaje de programación con los Tokens provenientes del analizador léxico.
Unidad de Aprendizaje 4: Definición formal de una gramática
Los estudiantes utilizarán las reglas gramaticales que determinan el orden en que deben ir las cadenas aceptadas en un determinado lenguaje.
Resumen de Unidad 1
Compiladores y Lenguajes Formales
Compiladores y Lenguajes de Programación
En esta sección, se abordan los fundamentos esenciales relacionados con los compiladores y los lenguajes de programación. Se examina el papel de los traductores, incluyendo tanto intérpretes como compiladores, en la transformación del código fuente en código ejecutable. Asimismo, se proporciona una exposición detallada sobre la función y la importancia de los compiladores en el proceso de traducción.
Análisis Léxico y Procesamiento de Cadenas
El análisis léxico se presenta como la etapa inicial y fundamental en el proceso de traducción. Se discuten los aspectos clave de esta fase, que incluyen la lectura del código fuente y las funciones del analizador léxico. Además, se exploran los conceptos de componentes léxicos, como lexemas y tokens, y se examina el proceso de reconocimiento de estos componentes para generar tokens en un lenguaje de programación.
Lenguajes Formales y Expresiones Regulares
En esta sección, se introduce el concepto de lenguaje simbólico y se exploran sus componentes básicos, como la concatenación, la potencia y las cerraduras en conjuntos y cadenas. Se define el concepto de lenguaje, así como las operaciones fundamentales entre lenguajes. Además, se profundiza en el uso de expresiones regulares como herramientas para describir patrones en cadenas de texto, incluyendo las operaciones y extensiones asociadas.
Expresiones Regulares para Tokens de Lenguajes de Programación
Se analiza el uso específico de expresiones regulares en la identificación de tokens en lenguajes de programación. Se categorizan los tokens, como palabras reservadas, símbolos especiales, identificadores y literales, y se presentan ejemplos de expresiones regulares para reconocer números enteros y reales, así como identificadores y tokens específicos de un lenguaje.
Autómatas y Reconocimiento de Lenguajes
Finalmente, se introduce el concepto de autómatas finitos deterministas (DFA) como herramientas para el reconocimiento de lenguajes. Se analizan los componentes esenciales de un DFA, incluyendo estados, estado inicial y estados finales, así como su representación mediante tabla y diagrama. Además, se explora el concepto de lenguaje reconocido por un autómata finito determinista.
Fundamentos de compiladores y lenguajes de Programación
Generación de Lenguajes de Programación
La generación de lenguajes de programación es un área de estudio en la teoría de lenguajes de programación que se centra en la creación de nuevos lenguajes de programación y en la mejora de los existentes.
¿Por qué Generar Nuevos Lenguajes de Programación?
Aunque ya existen muchos lenguajes de programación, la generación de nuevos lenguajes puede ser necesaria para satisfacer necesidades específicas, como mejorar la eficiencia, facilitar ciertos tipos de programación, o proporcionar nuevas formas de abstracción.
Diseño de Lenguajes de Programación
El diseño de un nuevo lenguaje de programación implica tomar decisiones sobre su sintaxis, semántica y características de tipo. Esto puede incluir la elección entre un enfoque imperativo o funcional, la definición de la estructura de los programas y la determinación de cómo se manejarán los errores.
Implementación de Lenguajes de Programación
Una vez diseñado el lenguaje, el siguiente paso es implementarlo. Esto implica la creación de un compilador o intérprete que pueda traducir programas escritos en el nuevo lenguaje a un formato que pueda ser ejecutado por una máquina.
Herramientas para la Generación de Lenguajes de Programación
Existen varias herramientas que pueden ayudar en la generación de lenguajes de programación, como los generadores de analizadores léxicos y sintácticos. Estas herramientas pueden automatizar partes del proceso de implementación del lenguaje.
Ojo
La generación de lenguajes de programación es un campo importante y en constante evolución en la teoría de lenguajes de programación. A través de la generación de nuevos lenguajes, los programadores pueden continuar empujando los límites de lo que es posible en la programación.
Introducción a los compiladores
Fases de un Compilador
Un compilador es una herramienta fundamental en el proceso de transformar un programa escrito en un lenguaje de alto nivel en código ejecutable por una computadora. Este proceso se divide en varias etapas que conforman las fases del compilador. A continuación, se detallan estas fases y su importancia en el proceso de compilación:
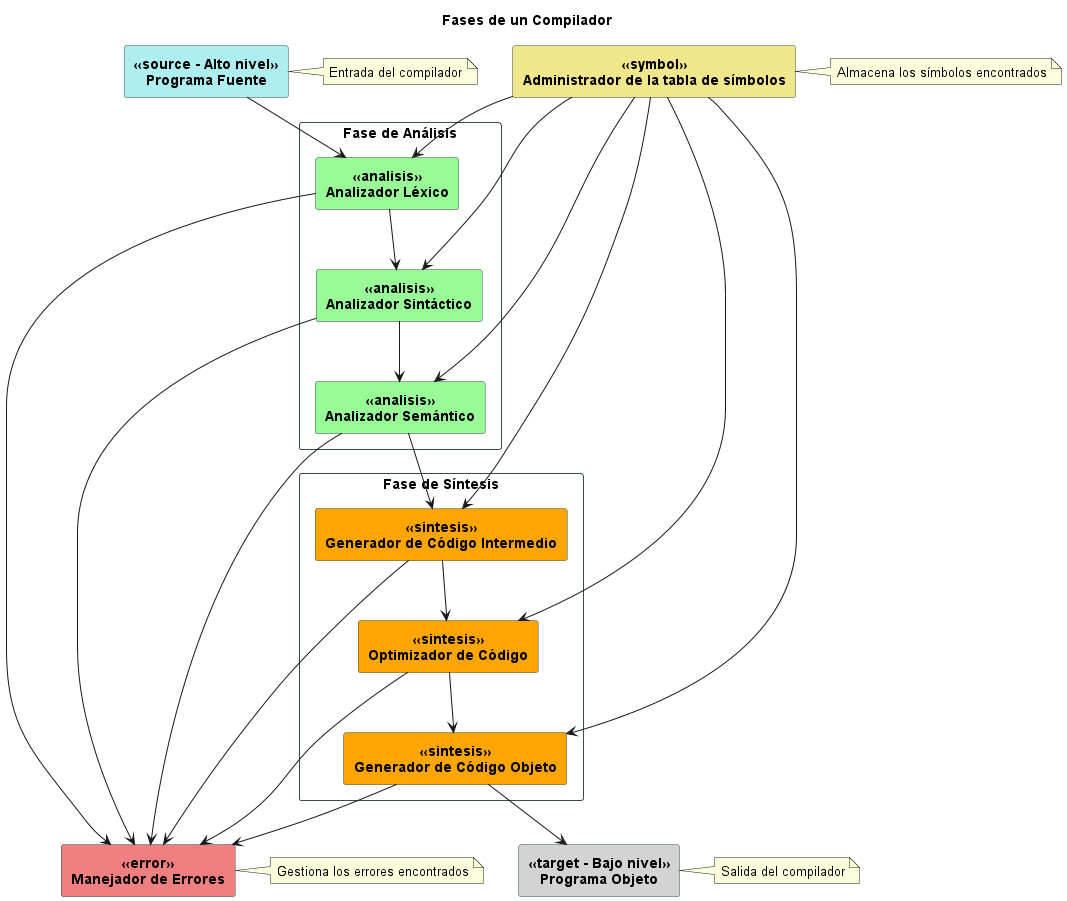 El diagrama muestra las fases de un compilador, que son los pasos que se siguen para transformar un programa fuente en un programa objeto.
El diagrama muestra las fases de un compilador, que son los pasos que se siguen para transformar un programa fuente en un programa objeto.
Programa Fuente
El programa fuente es el punto de partida del proceso de compilación. Consiste en el código escrito por el programador en un lenguaje de alto nivel, como C++, Java o Python.
Administrador de la Tabla de Símbolos
Durante el análisis del programa fuente, se encuentran diversos símbolos, como variables, constantes y funciones. El administrador de la tabla de símbolos se encarga de almacenar esta información para su posterior uso en etapas posteriores del compilador.
La primera fase del compilador es el análisis léxico. Aquí, el programa fuente se divide en unidades léxicas llamadas tokens, que representan los elementos básicos del lenguaje de programación, como palabras clave, identificadores, operadores y símbolos.
El analizador sintáctico toma la secuencia de tokens generada por el analizador léxico y verifica que siga las reglas gramaticales del lenguaje de programación. Esto garantiza que la estructura del programa sea correcta desde el punto de vista sintáctico.
Una vez que la estructura sintáctica del programa se ha validado, entra en juego el analizador semántico. Este componente verifica que el programa tenga sentido desde un punto de vista semántico. Por ejemplo, se asegura de que las variables estén declaradas antes de ser utilizadas y que los tipos de datos sean compatibles en las operaciones.
El generador de código intermedio transforma el programa fuente en una representación intermedia, más abstracta y fácil de manipular. Esta etapa facilita la optimización del código y la generación del código objeto final.
El optimizador de código mejora la representación intermedia del programa para hacerlo más eficiente en términos de tiempo de ejecución y consumo de recursos.
Finalmente, el generador de código objeto traduce la representación intermedia del programa en código objeto, que es un conjunto de instrucciones ejecutables por la máquina objetivo.
Manejador de Errores
Durante todo el proceso de compilación, es posible que se encuentren errores léxicos, sintácticos o semánticos en el programa fuente. El manejador de errores se encarga de identificar, reportar y gestionar estos errores de manera adecuada.
Programa Objeto
El resultado final del proceso de compilación es el programa objeto, que consiste en el código ejecutable generado a partir del programa fuente. Este programa objeto puede ser ejecutado directamente por la máquina objetivo.
Conocimientos Adicionales
Código Fuente
El código fuente es el conjunto de instrucciones y declaraciones escritas en el lenguaje de programación que los desarrolladores utilizan para crear programas y aplicaciones. Este código es legible y comprensible para los humanos. Los programadores escriben el código fuente utilizando un editor de texto o un entorno de desarrollo integrado (IDE). El código fuente debe ser compilado o interpretado para convertirlo en un formato que la computadora pueda ejecutar.
Bytecode
El bytecode es un tipo de código que ha sido traducido desde el código fuente a un formato de bajo nivel que es más fácil para una máquina virtual ejecutar. No es código de máquina (que sería específico para un tipo de hardware), sino un paso intermedio entre el código fuente y el código de máquina.
El bytecode es típicamente utilizado en lenguajes de programación como Java y Python. En Java, por ejemplo, el compilador javac traduce el código fuente a bytecode, que luego puede ser ejecutado en cualquier máquina que tenga instalada la Máquina Virtual de Java (JVM), independientemente del sistema operativo o la arquitectura de hardware subyacente.
Si no existieran los compiladores, traductores e intérpretes
Si no existieran los compiladores, traductores e intérpretes, los programadores tendrían que escribir código directamente en lenguaje de máquina, que es una tarea muy compleja y propensa a errores. El lenguaje de máquina es específico para cada tipo de hardware, por lo que los programadores tendrían que escribir diferentes versiones de su código para cada tipo de computadora.
Además, sin los compiladores e intérpretes, los lenguajes de programación de alto nivel como Python, Java, C++, entre otros, no existirían. Estos lenguajes son más fáciles de aprender y usar que el lenguaje de máquina, y permiten a los programadores escribir código de manera más eficiente y con menos errores.
Compilador: Conceptos Básicos
Compilar y Compilador
| Compilar | Compilador |
|---|---|
| Definición: La compilación es el proceso de transformar un programa fuente en un programa objeto ejecutable. | Definición: Un compilador es una herramienta que se utiliza para traducir un programa fuente escrito en un lenguaje de alto nivel a un programa objeto ejecutable, puede ser en binario o en código intermedio como el bytecode. |
| Objetivo: El objetivo de la compilación es generar un programa ejecutable a partir del código fuente. | Objetivo: El objetivo de un compilador es generar un programa ejecutable a partir del código fuente. |
| Resultado: El resultado de la compilación es un programa objeto que puede ser ejecutado por la máquina objetivo. | Funcionamiento: Un compilador consta de varias etapas, como el análisis léxico, sintáctico, semántico, la generación de código intermedio y la optimización de código. |
| Pasos: La compilación consta de varias etapas, como el análisis léxico, sintáctico, semántico, la generación de código intermedio y la optimización de código. | Tipos: Existen diferentes tipos de compiladores, como los compiladores de una sola pasada, los compiladores de múltiples pasadas, los compiladores de optimización, etc. |
| Herramientas: Para compilar un programa, se utiliza un compilador específico para el lenguaje de programación en el que está escrito el programa. | Ejemplos: Algunos ejemplos de compiladores populares son GCC (GNU Compiler Collection), Clang, Visual C++, etc. |
Diferencias entre compilador e intérprete
| Diferencias | Compilador | Intérprete |
|---|---|---|
| Proceso | El compilador traduce todo el programa a código máquina antes de ejecutarlo. | El intérprete traduce y ejecuta el programa línea por línea en tiempo real. |
| Ejecución | El programa compilado se ejecuta más rápido ya que no necesita realizar la traducción en tiempo real. | El programa interpretado puede ser más lento ya que realiza la traducción en tiempo real durante la ejecución. |
| Dependencias | El programa compilado no depende del compilador una vez que se ha generado el programa objeto. | El programa interpretado depende del intérprete para su ejecución. |
| Portabilidad | El programa compilado puede ser ejecutado en cualquier máquina compatible con la arquitectura del programa objeto. | El programa interpretado puede requerir un intérprete específico para cada plataforma en la que se desee ejecutar. |
| Errores | Los errores de compilación se detectan antes de la ejecución del programa. | Los errores de interpretación se detectan durante la ejecución del programa. |
| Modificaciones | Para realizar cambios en el programa, es necesario recompilarlo. | Los cambios en el programa pueden realizarse directamente sin necesidad de recompilarlo. |
| Ejemplos de Lenguajes | C, C++, Java, etc. | Python, Ruby, JavaScript, etc. |
Estructura de un compilador
De manera general el proceso de compilacion consta de 2 fases principales:
-
Análisis: En esta fase, el compilador analiza el código fuente para identificar la estructura del programa y generar una representación intermedia del mismo. Esta fase se divide en tres subfases: análisis léxico, análisis sintáctico y análisis semántico.
-
Síntesis: En esta fase, el compilador genera el código objeto a partir de la representación intermedia generada en la fase de análisis. Esta fase también puede incluir la optimización del código generado.
Ventajas y Desventajas de la Compilación
Ventajas de la Compilación
-
Rendimiento: Los programas compilados suelen ser más rápidos y eficientes en tiempo de ejecución porque el código se optimiza durante la compilación.
-
Seguridad: El código fuente no está disponible en el programa compilado, lo que puede proteger la propiedad intelectual.
-
Independencia del lenguaje fuente: Una vez compilado, el programa puede ejecutarse en cualquier plataforma que soporte el código de máquina generado.
Desventajas de la Compilación
-
Tiempo de compilación: Los programas grandes pueden llevar mucho tiempo para compilar.
-
Dependencia de la plataforma: El código compilado es específico de la plataforma para la que se compiló. Si se necesita ejecutar el programa en diferentes plataformas, se debe compilar por separado para cada una.
-
Dificultad para depurar: Los errores en tiempo de ejecución pueden ser más difíciles de rastrear porque el código que se está ejecutando es diferente del código fuente original.
Fase de Análisis (El Frontend del Compilador)
La fase de análisis, también conocida como frontend del compilador, es el punto de partida donde el código fuente es sometido a un exhaustivo escrutinio léxico, sintáctico y semántico. Esta fase da lugar a la creación de una representación intermedia del programa fuente y a la construcción de la tabla de símbolos, que servirán como entrada para la fase de síntesis.

Subfases de Análisis
1. Análisis Léxico
El análisis léxico, la primera subfase del frontend, se encarga de garantizar que todas las palabras del código se ajusten al alfabeto del lenguaje y estén definidas dentro del mismo. Aquí, el código fuente se descompone en unidades léxicas llamadas tokens, que representan las entidades básicas del lenguaje de programación.
2. Análisis Sintáctico
El análisis sintáctico verifica que cada estructura del código respete las reglas gramaticales del lenguaje, asegurando que tenga un sentido estructuralmente correcto. Este proceso se encarga de construir la estructura jerárquica del programa, utilizando la secuencia de tokens generada por el análisis léxico.
3. Análisis Semántico
El análisis semántico se adentra en el significado del código, verificando que las construcciones del programa tengan coherencia semántica. Se asegura de que las variables estén correctamente declaradas, que los tipos de datos sean compatibles y que las operaciones tengan sentido en el contexto del programa.
Análisis Léxico: La Puerta de Entrada al Compilador
El análisis léxico representa el primer paso en el proceso de compilación, donde el programa fuente es sometido a un minucioso escrutinio para identificar sus elementos básicos y significativos. Esta fase, también conocida como frontend del compilador, desempeña un papel fundamental al transformar el código fuente en una secuencia de tokens, los cuales servirán como base para las etapas posteriores del proceso de compilación.
Proceso de Análisis Léxico
El análisis léxico se desarrolla en varias etapas que garantizan una adecuada interpretación del código fuente:
-
Lectura del Programa Fuente: En esta etapa inicial, el compilador lee el programa fuente en su totalidad.
-
Eliminación de Espacios en Blanco y Comentarios: Se eliminan los espacios en blanco, tabulaciones y saltos de línea para simplificar el código. Asimismo, los comentarios son descartados, ya que no son relevantes para el proceso de análisis.
-
Agrupación en Tokens: Los caracteres restantes se agrupan en unidades llamadas tokens. Un token es una secuencia de caracteres que representa una unidad semántica significativa dentro del código.
Tokens
Un token es una secuencia de caracteres que forman una unidad significativa
Tipos de Tokens
-
Palabras Reservadas: Representan instrucciones o comandos predefinidos en el lenguaje de programación, como IF, THEN, ELSE.
-
Operadores: Incluyen símbolos que denotan operaciones o relaciones entre entidades, como +, >=, :=.
-
Identificadores: Son cadenas de caracteres que representan nombres de variables, funciones o elementos definidos por el usuario, como Plazo, Tasa.
-
Constantes: Representan valores fijos, como números enteros o decimales, por ejemplo, 30, 100.
Interacción con el Análisis Sintáctico
La interacción entre el análisis léxico y el análisis sintáctico es crucial para garantizar la comprensión correcta del código. Esta interacción puede tomar varias formas:
- Ambas actividades se ejecutan en modo batch, procesando todo el código de una sola vez.
- Son actividades concurrentes, lo que permite una mayor eficiencia en el análisis.
- Ambas actividades pueden integrarse como rutinas del generador de código.
- El análisis léxico puede ser una rutina del análisis sintáctico, proporcionando los tokens necesarios para su procesamiento.
Ejemplo Práctico
Esta tabla muestra cómo se identifican los tokens en un programa fuente.
| Token | Identificación del token |
|---|---|
| ID | 27 |
| CTE | 28 |
| IF | 59 |
| THEN | 60 |
| ELSE | 61 |
| + | 70 |
| / | 73 |
| >= | 80 |
| := | 85 |
ID es un identificador, CTE es una constante y los demás son palabras reservadas u operadores.
Tomemos como ejemplo el siguiente código:
if Plazo >= 30
then Tasa := Base + Recargo / 100
else Tasa := Base
Aquí, podemos observar cómo se divide en tokens:
[IF] [Plazo] [>=] [30]
[THEN] [Tasa] [:=] [Base] [+] [Recargo] [/] [100]
[ELSE] [Tasa] [:=] [Base]
Este código se convierte en una secuencia de tokens significativos para el compilador, donde cada token se asocia con una identificación única:
[59] [27] [80] [28]
[60] [27] [85] [27] [70] [27] [73] [28]
[61] [27] [85] [27]
En este ejemplo, el token "IF" se identifica con el número [59], el identificador "Plazo" con el número [27], el operador ">=" con el número [80], y así sucesivamente.
Diferencia entre Lexema y Token
En el contexto del análisis léxico, es importante comprender la diferencia entre lexema y token:
-
Lexema: Es la secuencia de caracteres que representa una unidad léxica en el código fuente. Por ejemplo, en el código
Plazo >= 30, el lexema "Plazo" representa un identificador. -
Token: Es la combinación de un lexema y una identificación única que representa una unidad semántica en el código fuente. Por ejemplo, en el código
Plazo >= 30, el token asociado al lexema "Plazo" es [27], que representa un identificador.
La tabla a continuación muestra algunos ejemplos de lexemas y sus correspondientes tokens:
| Lexema | Token |
|---|---|
| Plazo | [27] |
| >= | [80] |
| 30 | [28] |
| IF | [59] |
| THEN | [60] |
| ELSE | [61] |
| + | [70] |
| / | [73] |
| := | [85] |
Otro ejemplo: En el código int x = 5;, int, x, =, 5, y ; son lexemas. Los tokens correspondientes podrían ser palabra clave: int, identificador: x, operador de asignación: =, constante entera: 5, y punto y coma: ;.
El lexema es la representación textual de una unidad léxica, mientras que el token es la combinación del lexema y su identificación única en el análisis léxico.
Ejercicio
Toma como referencia el programa mostrado y la tabla adjunta.
if Plazo >= 30 then
Tasa := Base + Recargo / 100
else
Tasa := Base
| Token | Identificación del token |
|---|---|
| ID | 27 |
| CTE | 28 |
| IF | 59 |
| THEN | 60 |
| ELSE | 61 |
| + | 70 |
| / | 73 |
| >= | 80 |
| := | 85 |
Expresare el programa en:
- lexemas
- en código numérico de los tokens
- en tokens
- Scanner el programa indicando el número de línea, indicar si es palabra reservada, indicar el token, en los identificadores indicar el número de línea y en las constantes indicar su valor.
Desarrollo
- Lexemas:
Los lexemas encontrados son:
if, Plazo, >=, 30, then,
Tasa, :=, Base, +, Recargo, /, 100,
else,
Tasa, :=, Base
- Código numérico de los tokens:
Los códigos numéricos de los tokens son:
59, 27, 80, 28, 60,
27, 85, 27, 70, 27, 73, 28,
61,
27, 85, 27
- Tokens:
Los tokens son:
[59], [27], [80], [28], [60],
[27], [85], [27], [70], [27], [73], [28],
[61],
[27], [85], [27]
- Scanner del programa por línea:
| Línea | Tipo | Lexema | Token |
|---|---|---|---|
| 1 | Palabra reservada | IF | [59] |
| 1 | Identificador | Plazo | [27] |
| 1 | Operador | >= | [80] |
| 1 | Constante | 30 | [28] |
| 1 | Palabra reservada | THEN | [60] |
| 2 | Identificador | Tasa | [27] |
| 2 | Operador | := | [85] |
| 2 | Identificador | Base | [27] |
| 2 | Operador | + | [70] |
| 2 | Identificador | Recargo | [27] |
| 2 | Operador | / | [73] |
| 2 | Constante | 100 | [28] |
| 3 | Palabra reservada | ELSE | [61] |
| 4 | Identificador | Tasa | [27] |
| 4 | Operador | := | [85] |
| 4 | Identificador | Base | [27] |
Fase de Síntesis (El Backend del Compilador)
La fase de síntesis, también conocida como backend del compilador, es donde se genera el programa destino a partir del código fuente, su representación intermedia y la tabla de símbolos obtenida en la fase de análisis.

Subfases de Síntesis
1. Generación de Código Intermedio
En esta subfase, se recibe la representación intermedia del programa y se transforma en una forma más abstracta y fácil de optimizar. El código intermedio tiende a ser independiente de la máquina objetivo y facilita las etapas posteriores de optimización y generación de código objeto.
2. Optimización de Código
La optimización de código se encarga de mejorar la representación intermedia del programa para que sea más eficiente en términos de tiempo de ejecución y consumo de recursos. Transforma fragmentos de código en otros equivalentes pero más eficientes, utilizando técnicas como la eliminación de código redundante o la reorganización de operaciones.
3. Generación de Código Objeto
En la fase final, el generador de código objeto traduce la representación intermedia del programa en código ejecutable para la máquina objetivo. Este código objeto es el resultado final del proceso de compilación y puede ser ejecutado directamente por la computadora.
Elementos Básicos de los Lenguajes Formales Alfabetos, Cadenas y Lenguajes
Lenguajes Regulares y Fundamentos Lingüísticos
Alfabetos
Un alfabeto se define como un conjunto no vacío de símbolos o caracteres. Se denota con la letra griega mayúscula Σ (sigma), y se cumple que Σ ≠ ∅, lo que significa que su cardinalidad (|Σ|) es mayor que cero.
Ejemplos de alfabetos:
- Σ = {a, b, c, ..., z}: Alfabeto del lenguaje español.
- Σ = {0, 1, 2, ..., 9}: Alfabeto numérico.
- Σ = {0, 1}: Alfabeto binario computacional.
- Σ = {0, 1, ..., 9, A, B, ..., F}: Alfabeto hexadecimal.
Un símbolo o carácter es un elemento perteneciente a un alfabeto dado. Por ejemplo, si X ∈ Σ, entonces X es un símbolo del alfabeto Σ.
Cadenas
Las cadenas, también conocidas como palabras o strings, son yuxtaposiciones de elementos de un alfabeto. Una cadena se forma mediante la concatenación de símbolos de un alfabeto dado.
Ejemplos de cadenas en el alfabeto binario Σ = {0, 1}:
- W1 = 0, 1, 1, 0, 1
- W2 = 0
- W3 = ε (cadena vacía, representada por el símbolo épsilon)
El tamaño de una cadena se determina por el número de símbolos que la componen.
Por ejemplo:
- |W1| = 5
- |W2| = 1
- |ε| = 0
Concatenación de Cadenas
La operación de concatenación de cadenas se denota mediante la yuxtaposición de las mismas. Si X = a1, a2, ..., an y Y = b1, b2, ..., bm, entonces la concatenación de X e Y se representa como XY = a1, a2, ..., an, b1, b2, ..., bm.
Además, se pueden definir operaciones sobre conjuntos de cadenas, como la clausura de Kleene (Σ*) y la clausura de Kleene positiva (Σ+). La clausura de Kleene de un alfabeto Σ se define como Σ* = Σ0 ∪ Σ1 ∪ Σ2 ∪ ..., donde Σ0 = {ε} y Σn representa todas las cadenas de longitud n formadas con símbolos de Σ. Por otro lado, la clausura de Kleene positiva excluye la cadena vacía: Σ+ = Σ* - {ε}.
Es importante tener en cuenta que el orden de las cadenas en la concatenación importa. Por ejemplo:
W = "01"
X = "10"
Concatenación: WX = "0110"
Además, la longitud de la cadena resultante de la concatenación es igual a la suma de las longitudes de las cadenas originales:
|WX| = |W| + |X|
Ejemplo de Concatenación de Cadenas
En el manejo de cadenas, es común realizar operaciones como 'calcular el cuadrado de una cadena' o 'encontrar subcadenas'.
Consideremos las cadenas:
W = "LETRA"
X = "PALABRA"
Para calcular el cuadrado de una cadena, simplemente concatenamos la cadena consigo misma:
(W)^2 = "LETRALETRA"
(X)^2 = "PALABRAPALABRA"
Y para encontrar la concatenación de los cuadrados de dos cadenas, simplemente concatenamos los cuadrados de las cadenas originales:
W = "01"
X = "10"
Concatenación: WX = "0110"
(WX)^2 = "01100110"
(W)^2 = "0101"
(X)^2 = "1010"
W^2X^2 = "01011010"
Subcadena
Una subcadena es una secuencia de caracteres contenida dentro de una cadena más larga. Por ejemplo, para la cadena "LETRA", las subcadenas posibles incluyen "LE", "ET", "TRA", entre otras. Es importante mencionar que la cadena vacía también se considera una subcadena.
Y0 = ""
Y1 = "L"
Y2 = "E"
Y3 = "T"
Y4 = "R"
Y5 = "A"
Y6 = "LE"
Y7 = "ET"
Y8 = "TR"
Y9 = "RA"
Y10 = "LET"
Y11 = "ETR"
Y12 = "TRA"
Y13 = "LETR"
Y14 = "ETRA"
En total, hay 15 subcadenas posibles para la cadena "LETRA". No se incluye la cadena 'LETRA' como subcadena dado que es la cadena original.
Lenguajes
Un lenguaje sobre un alfabeto Σ es cualquier subconjunto de la clausura de Kleene de ese alfabeto (Σ*). Se denota como L ⊆ Σ*. Por ejemplo, el lenguaje español es un subconjunto de todas las combinaciones posibles del alfabeto formado por las letras seria [A-Za-zñÑ].
Es posible realizar operaciones sobre los lenguajes, como la concatenación. Si L1 y L2 son lenguajes, su concatenación se define como L1L2 = {XY | X ∈ L1, Y ∈ L2}.
Lenguaje Regular
Introducción
Los lenguajes regulares son ampliamente utilizados en el procesamiento de lenguajes de programación y en la búsqueda de cadenas de caracteres o secuencias específicas. Las expresiones regulares (E.R) proporcionan una manera sencilla de describir estas secuencias de caracteres. La búsqueda de caracteres o secuencias concretas de caracteres en documentos forma parte de las tareas estándar y recurrentes de la tecnología de la información. Por lo general, el objetivo es modificar o sustituir fragmentos de texto o líneas de código, cuya complejidad aumenta en función de las veces que la secuencia de caracteres aparece en el documento.
Lenguaje Regular
Un lenguaje regular es una secuencia de elementos que cumple y verifica las siguientes condiciones:
a ∈ Ventoncesaes una E.R. (dondeVes un alfabeto)- Si
XeYson E.R., entoncesX.Yes una E.R. (parte recursiva) - Si
XeYson E.R., entoncesX+Yes una E.R. (concatenación) - Si
Xes una E.R., entoncesX*es una E.R. (clausura de cualquier E.R. es una E.R.)
Esta definición indica que las expresiones regulares pueden contener:
- Letras del alfabeto que forman palabras.
- Concatenaciones, sumas, multiplicaciones y clausuras.
- La cadena vacía
λ(lambda). Siempre se incluye en las expresiones regulares.
Ejemplo 1:
Si V = {a, b, c}, algunas de las expresiones regulares que se pueden formar con este alfabeto son:
a + b*
(a + c)b
a*c*
a*(b + c)c
b(a + λ)
Ejemplo 2:
La expresión regular del lenguaje cuyas palabras están formadas por las letras del alfabeto V = {a, b} y terminan en "b" es:
(a + b)*b
Ejemplo 3:
La expresión regular del lenguaje cuyas palabras están formadas por las letras del alfabeto V = {a, b}, tienen longitud mayor a 2, la segunda letra es "a", y la antepenúltima es "b", es:
(a + b)a(a + b)*b(a + b)
Esta expresión regular se puede interpretar de la siguiente manera:
- La primera letra puede ser
aob. - Luego sigue obligatoriamente una
a. - Después, puede haber cualquier secuencia de
aobde cualquier longitud. - Posteriormente, viene una
b. - Finalmente, una
aob.
Ejemplo 4: La expresión regular del lenguaje cuyas palabras están formadas por las letras del alfabeto V = {a, b} y consisten en 3 o más letras "b" seguidas de una letra "a", es:
bbbb*a # Aqui la cuarta b pued ser vacia por la clausula de kleene
# o también:
bbb+a # Aqui la tercera b no puede ser vacia
Autómatas
Introducción a los Autómatas
Los autómatas son modelos abstractos de sistemas computacionales que pueden procesar entradas de manera controlada. Están compuestos por un conjunto finito de estados y una función de transición que define cómo el autómata cambia de un estado a otro en respuesta a las entradas.
Autómatas Finitos Deterministas (DFA)
Los Autómatas Finitos Deterministas (DFA) son un tipo específico de autómata caracterizado por tener un conjunto finito de estados, una única transición definida para cada estado y símbolo de entrada, y la capacidad de determinar de manera única su próximo estado.
Definición y Características
Un DFA se define formalmente como una tupla \(Q, \Sigma, \delta, q_0, F\), donde:
- \(Q\) es un conjunto finito de estados.
- \(\Sigma\) es un conjunto finito de símbolos de entrada (alfabeto).
- \(\delta\) es la función de transición, que mapea un estado y un símbolo de entrada a un estado.
- \(q_0\) es el estado inicial.
- \(F\) es un conjunto de estados finales o de aceptación.
Estados, Estado Inicial, Estados Finales
Los estados representan las diferentes situaciones en las que puede encontrarse el autómata durante su procesamiento. El estado inicial es el estado en el que el autómata comienza su ejecución, mientras que los estados finales son aquellos en los que el autómata finaliza su procesamiento y reconoce una cadena como válida.
Tabla y Diagrama de un Autómata Finito
Para representar la función de transición de un DFA, se utiliza comúnmente una tabla que muestra para cada estado y símbolo de entrada, el estado al que transita el autómata. También es común representar un DFA mediante un diagrama de estados, donde los nodos representan los estados y las aristas representan las transiciones entre ellos.
| Estado | 0 | 1 |
|---|---|---|
| A | B | C |
| B | C | A |
| C | A | B |
graph LR A -- 0 --> B A -- 1 --> C B -- 0 --> C B -- 1 --> A C -- 1 --> B C -- 0 --> A
Lenguaje Reconocido por un Autómata Finito Determinista
El lenguaje reconocido por un DFA es el conjunto de todas las cadenas que, al ser procesadas por el autómata, conducen a un estado final. El proceso de reconocimiento de cadenas por parte de un DFA implica seguir la función de transición del autómata secuencialmente para cada símbolo de la cadena de entrada, comenzando desde el estado inicial.
Definición del Lenguaje Reconocido
El lenguaje reconocido por un DFA se define como el conjunto de todas las cadenas que llevan al autómata desde su estado inicial a un estado final.
Proceso de Reconocimiento de Cadenas
Para reconocer una cadena dada, se inicia en el estado inicial del DFA y se sigue la función de transición para cada símbolo de la cadena. Si al finalizar la cadena el autómata se encuentra en un estado final, la cadena es reconocida; de lo contrario, la cadena es rechazada.
Esta versión incluye tablas para representar la función de transición y diagramas de estados utilizando Mermaid, lo que hace que el contenido sea más visualmente atractivo y fácil de entender para los lectores.